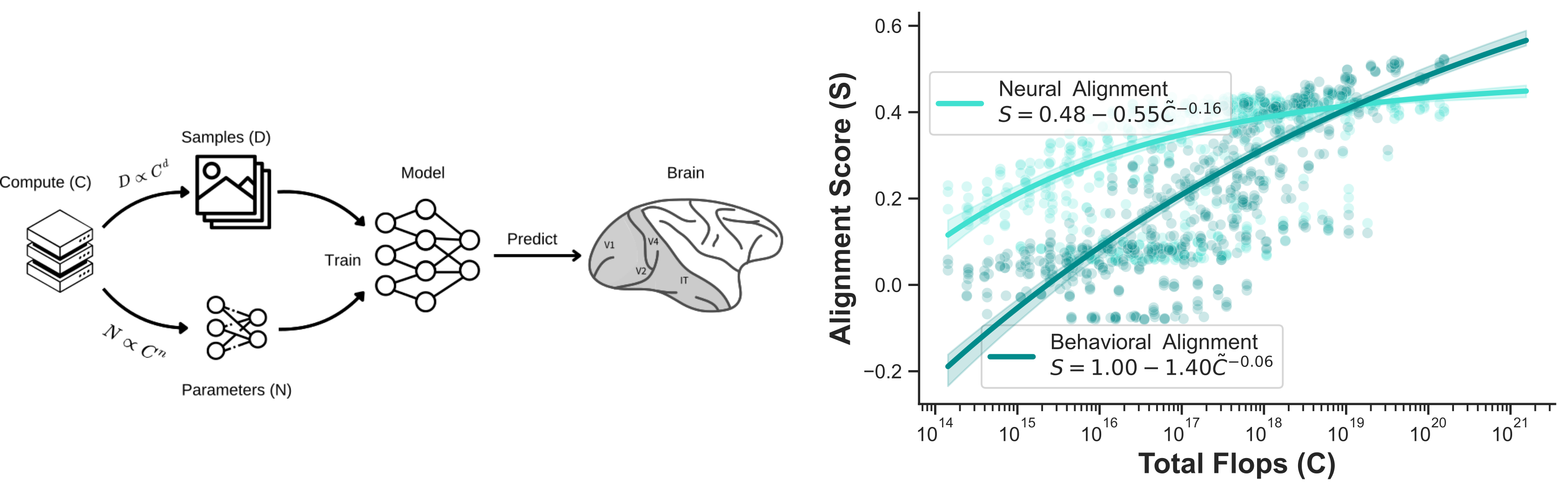
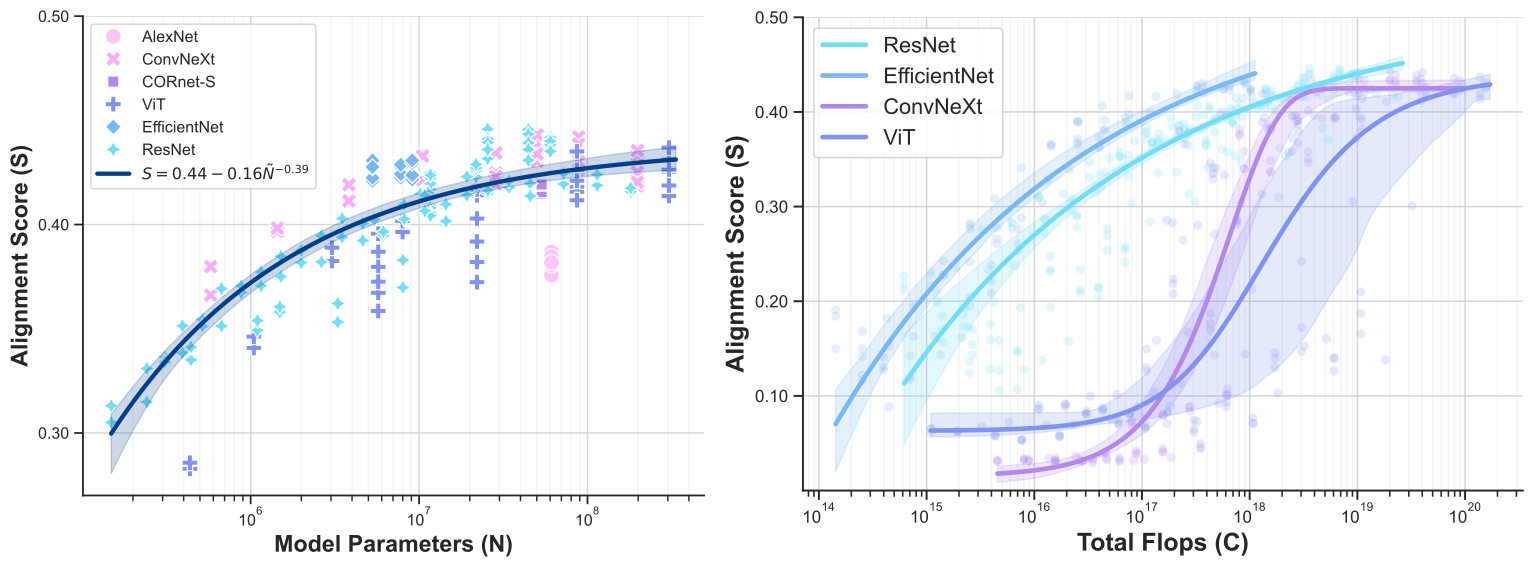
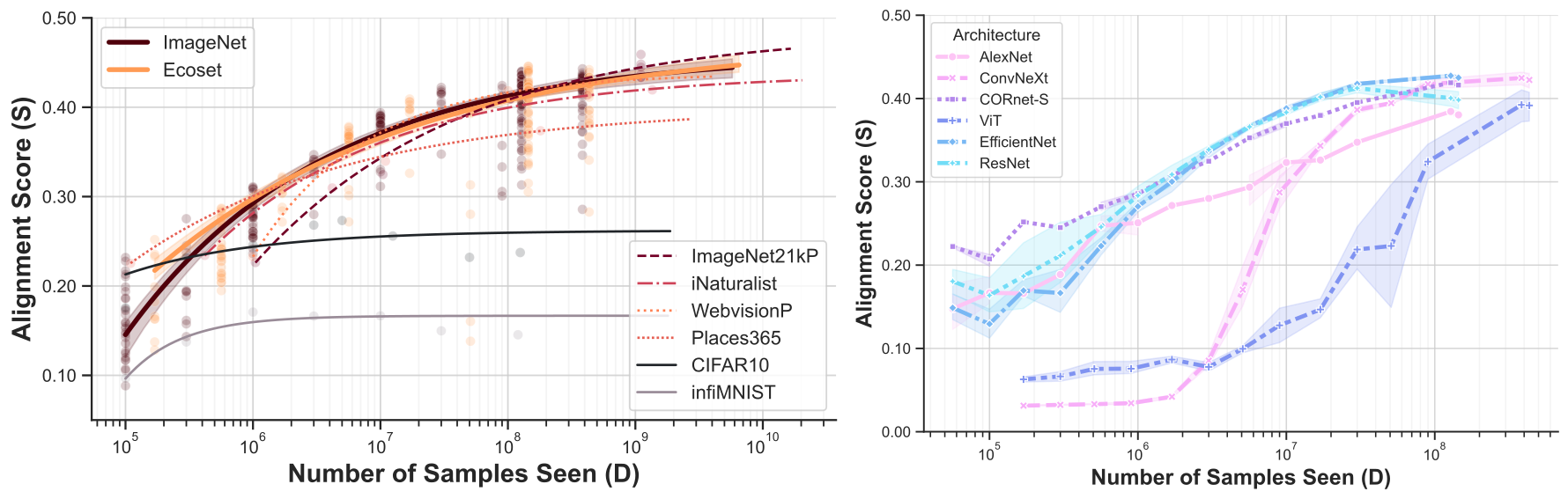
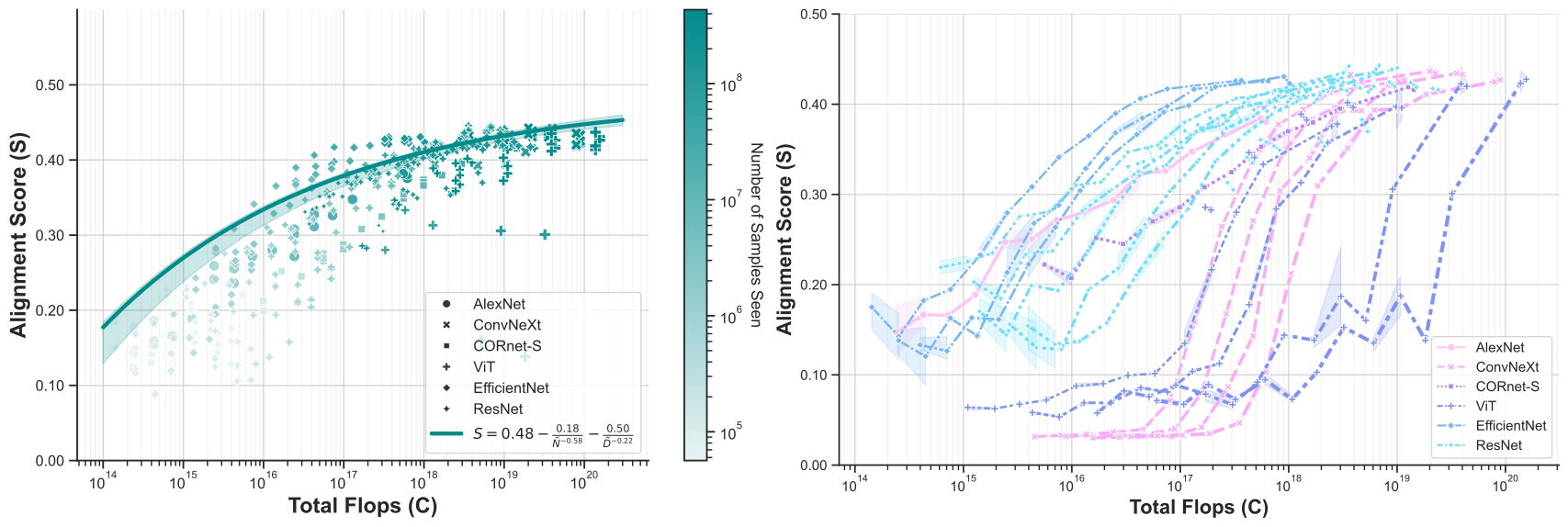
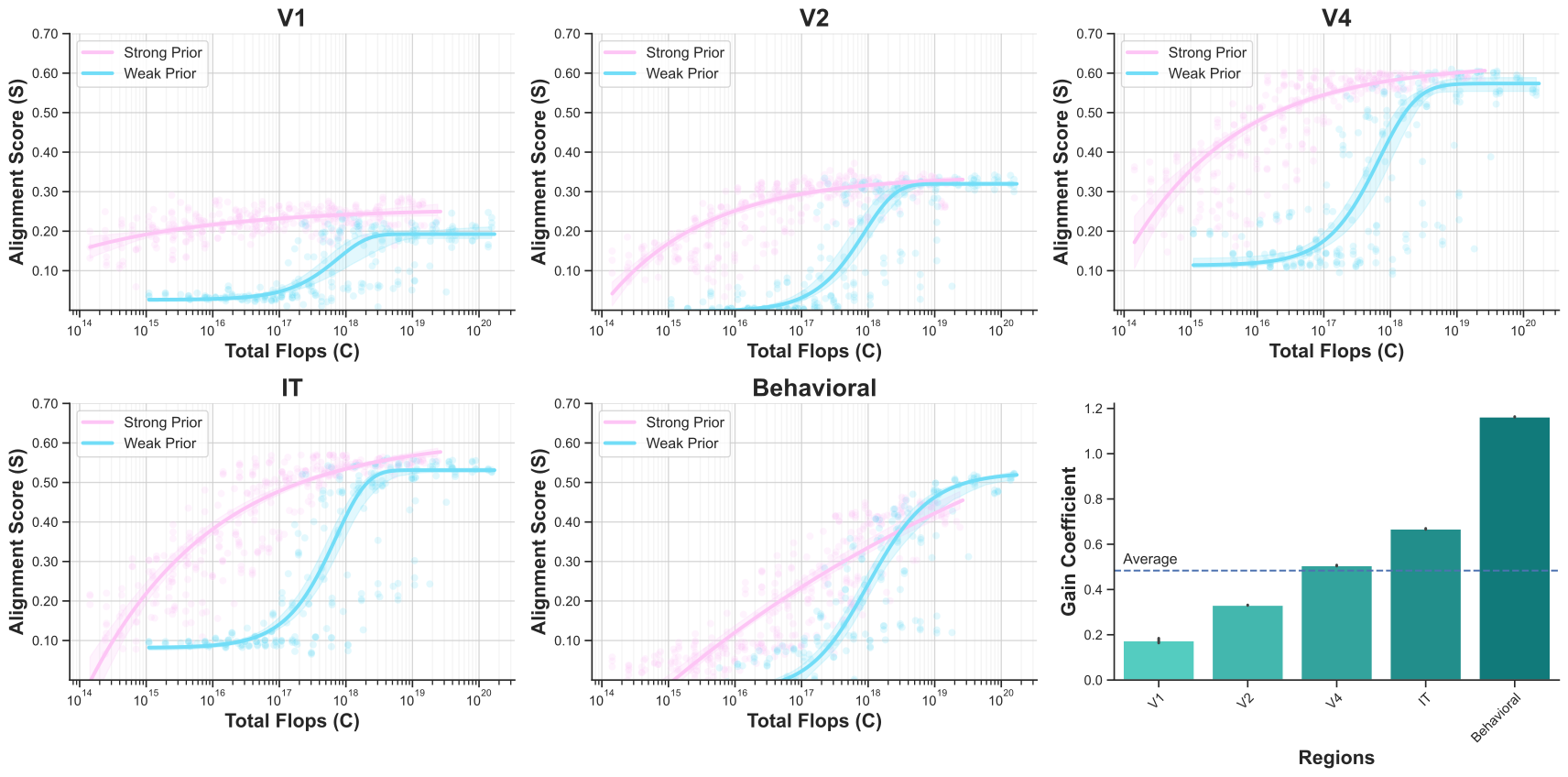
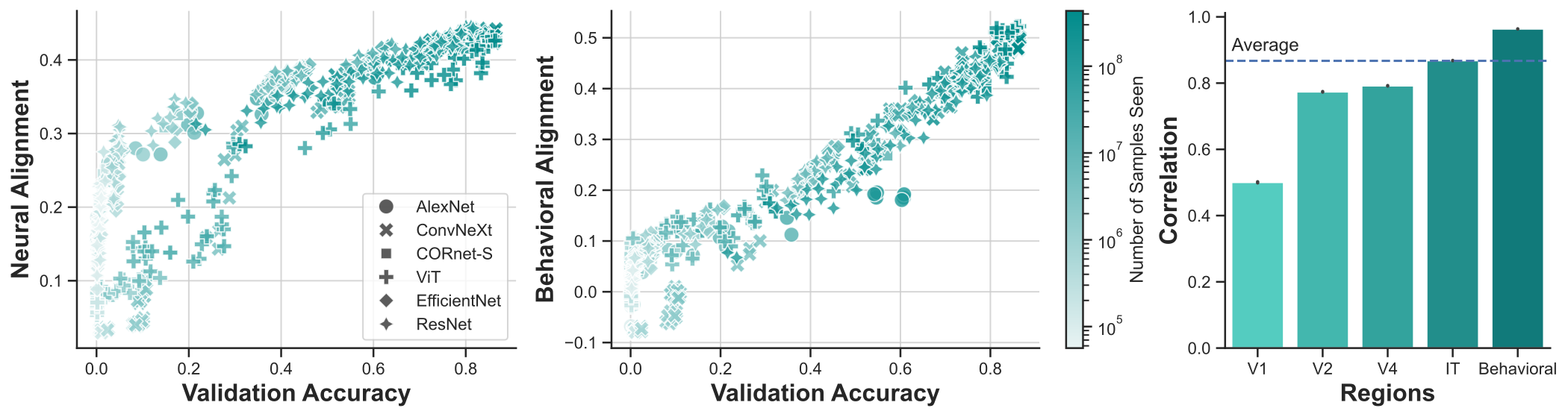
When trained on large-scale object classification datasets, certain artificial neural network models begin to approximate core object recognition behaviors and neural response patterns in the primate brain. While recent machine learning advances suggest that scaling compute, model size, and dataset size improves task performance, the impact of scaling on brain alignment remains unclear. In this study, we explore scaling laws for modeling the primate visual ventral stream by systematically evaluating over 600 models trained under controlled conditions on benchmarks spanning V1, V2, V4, IT and behavior. We find that while behavioral alignment continues to scale with larger models, neural alignment saturates. This observation remains true across model architectures and training datasets, even though models with stronger inductive biases and datasets with higher-quality images are more compute-efficient. Increased scaling is especially beneficial for higher-level visual areas, where small models trained on few samples exhibit only poor alignment. Our results suggest that while scaling current architectures and datasets might suffice for alignment with human core object recognition behavior, it will not yield improved models of the brain's visual ventral stream, highlighting the need for novel strategies in building brain models.